Supporting a new domain and new schema
hila Conversational Analytics (hCA) can connect to a database with a custom schema as a data source.
Custom schema restrictions
The following restrictions apply to custom schemas:
-
Only one fact table per hCA data source is supported. If you have more than one fact tables in your data model, you must define separate data sources for each fact table. For example, you can have a sales fact table containing data about revenue and expense transactions in an organization.
-
You may include any number of dimension tables in the data model, but they must form a star schema with the one fact table in the middle. For example, product, channel, and profit center dimensions with one-to-many relationships with sales fact tables to aggregate data on values from these dimensions. These dimension attributes can exist independently of the fact table in a star schema model or can be included as part of the fact table in a flattened, denormalized table.
-
A time span dimension must also be included to aggregate data by calendar and fiscal months, quarters, periods, halves, and so on. The source fact table must have a date or month to join with the time span dimension table.
-
The names of columns in fact and dimension tables should have meaningful business names and follow specific syntax requirements. For example, product dimension field names are like product_number, product_name, product_category. However, if the column names in your data model do not follow this convention, you can use the Labels.yaml file to define alternate names for the columns that appear in charts and tables in the hCA UI.
-
The names of foreign keys in fact and dimension tables must match. For example, if product_number is the primary key of the product dimension table, the fact table must also use the same product_name name for the foreign key.
-
In a star schema, all field names must be unique across fact and dimension tables.
1. Configure your custom schema
You need to set up the following files for running the custom schema with your instance of hila Conversational Analytics:
- config.yaml
- foundation.yaml
- labels.yaml
- prompts.yaml
- dimensions.jinja
- measures.jinja
- timespans.jinja
config.yaml
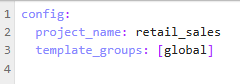
- project_name — A string to identify the name of the project.
- template_groups — In most cases, you can keep this as [global]. Other questions types depend on dimensions and measures for given types of analysis. Contact your services team if you need more info.
foundation.yaml
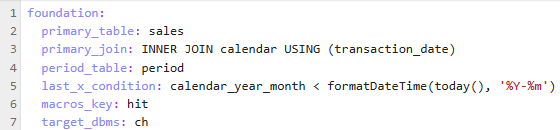
Contains information about primary fact table and associated time span dimension tables. Replace the names of tables to the first three lines depending on how you structure your time dimension table with respect to the primary table.
Only the first field is required, the rest are optional.
labels.yaml
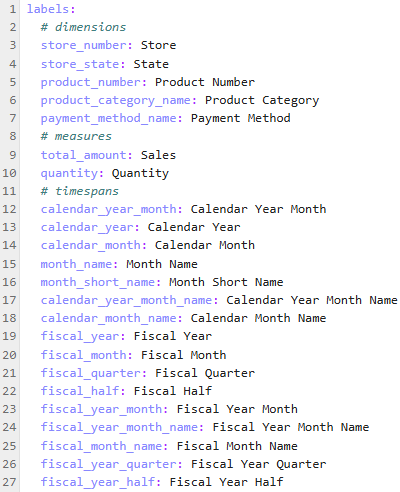
This file contains the column names as they appear in your data. You can modify the values to be any string. This lets you use more meaningful names for the columns in your data for when they appear in charts and tables in the hCA UI. For example, you can change product_number to be appear as Product Number or Product ID.
Everything below # timespans is optional.
prompts.yaml
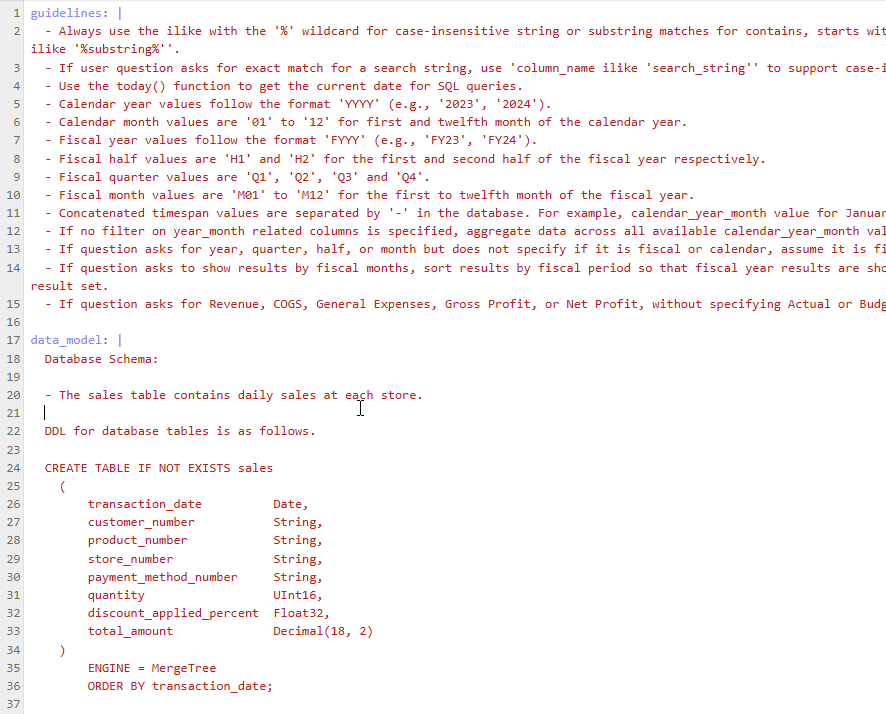
Each hCA data source needs a use case-specific text2sql prompt to send to LLMs.
-
guidelines — A list of standard guidelines that should work for you as-is, but you cna modify them to suit your needs. These guidelines are used to help the LLM understand the context of the data and how to answer questions about it.
-
data_model — Re-create your schema in this section, using the image above as a guide. Represent each table and column in this section as well as adding the primary key to the ENGINE expression.
-
dimension_values — Provides a list of dimension columns and their possible values to help LLMs figure out which column to use, especially if users only use values without providing dimension names in their questions.
dimensions.jinja

Defines for hCA how to format the LLM answers.
- dimensions — a list of dimension
Defines for hCA how to create data patterns based on dimension parameters and columns so hCA can infer the meaning of queries that are not explicitly defined.
- dimensions — a list of parameters for each dimension that includes:
- text — The name of the dimension.
- source — The name of the fact table.
- {{ lm.column(labels, ‘<column_name matching label to use>’)}} — fills in the string matching the column name you defined in the Labels.yaml file. These labels appear in charts and tables in the hCA UI.
- statement — Set to True if the dimension is relevant for profitability (P&L) questions. Default is False.
- plan — Set to True if the dimension is relevant for budget vs. forecast questions. Default is False.
- dimension_samples — populate items that belong to a given dimension.
- text — The name of the alternate column name from the Labels.yaml file.
- name — The name of the column name in the data.
- value: — The value of the sample item you want to associate with the column.
- next_text — The alternate name of the next column name. This helps hila coordinate answers across multiple columns in the same dimension.
- next_name — The next column name.
- dimension_pairs — Add a second value to the sample.
- text — The name of the alternate column name from the Labels.yaml file.
- name — The name of the column name in the data.
- first_value — The first value of the sample item you defined in the previous section.
- second_value — The other value of the sample item you want to add to that previous definition.
- dimension hierarchy — Defines hierarchies of categories and items within those categories.
- l1_text — The alternate column name of the first level of the hierarchy.
- l1_name — The column name of the category level of the hierarchy.
- l1_value — The value of the category level of the hierarchy.
- l2_text — The alternate column name of the item level of the hierarchy.
- l2_name — The column name of the item level of the hierarchy.
- l2_value — The value of the item level of the hierarchy.
measures.jinja
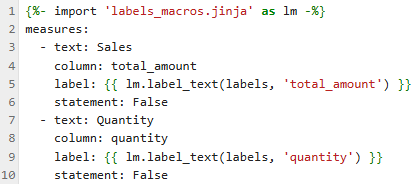
Defines measures in the underlying data model that are aggregated for analytics queries.
- measures — A list of measures that hCA can use to answer questions about the data. Each measure has the following properties:
- text — The alternate name of the column associated with the measure.
- column — The name of the column in the data that contains the measure.
- label — A template fills in the alternate column name you defined in the Labels.yaml file. These labels appear in charts and tables in the hCA UI.
- statement — Set to True if the measure is relevant for profitability (P&L) questions. Default is False.
- measure_pairs — A list of pairs of measures. Each pair has the following properties:
- text — The alternate name of the column associated with the measure.
- column — The name of the column in the data that contains the measure.
- first_value — The first value of the measure as defined above.
- second_value — The second value of the measure to add to the pair.
timespans.jinja
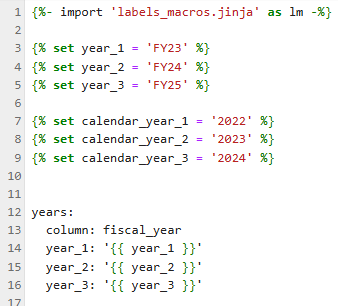
You can leave this file largely unchanged, but you should update the year_* and calendar_year_* values at each new year.
2. Ingest data with the custom schema
Contact your services team to get the custom schema notebook for where to add your files and how to run the notebook against your instance of hCA.